- In documented open web-data pipelines, extraction, language filtering, quality filtering, and deduplication remove the majority of crawled documents — the exact percentage varies by pipeline, but most public web content does not become meaningful training signal. Effective influence on model behaviour is even lower, because higher-quality sources are heavily upsampled (RefinedWeb, 2023; FineWeb, 2024).
- Tokenisation is not crawling — it happens only after quality filtering. Same text produces different token sequences across GPT, Llama, and Claude tokenisers.
- A trained model's weights are not stored embeddings. Model knowledge is encoded in weight matrices; embeddings are a computational intermediate, then discarded.
- Quality filters reward structural proxies of reliability: named authorship, schema markup, heading hierarchy, in-body source attribution, low boilerplate ratio — not human-readable quality.
- Optimising for base-model training and optimising for RAG retrieval are related but distinct objectives.
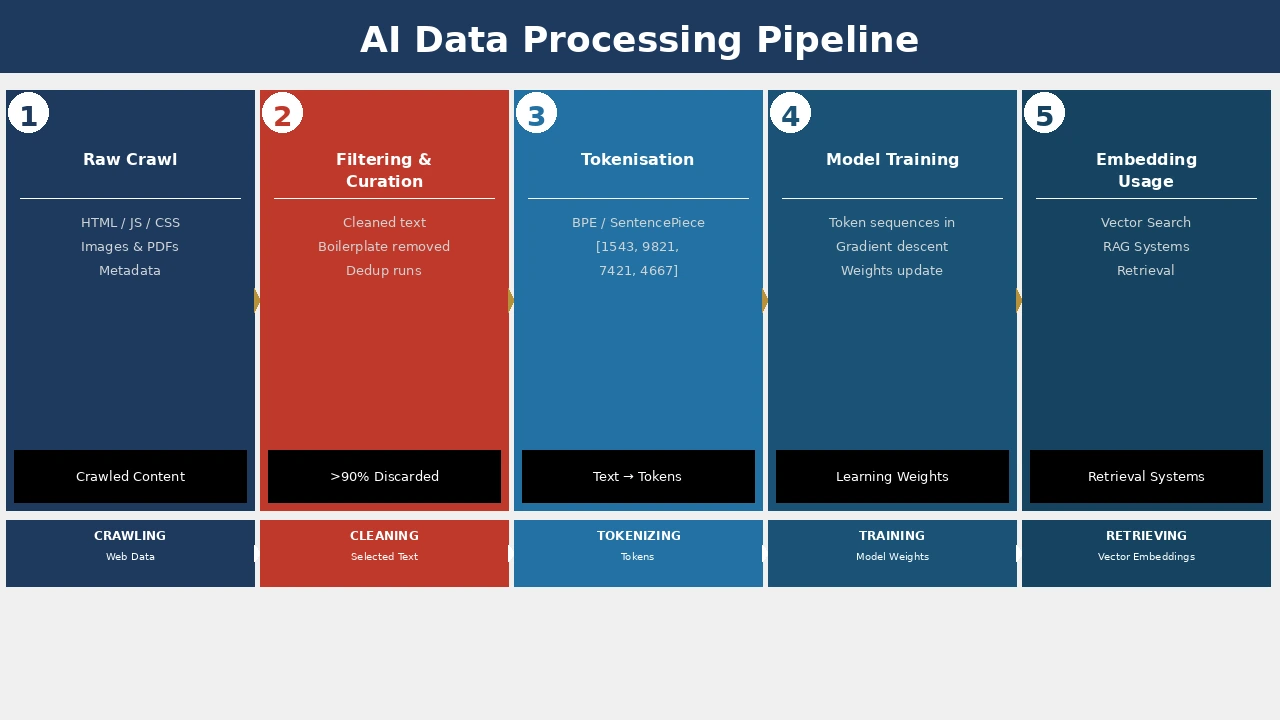
The image of AI "reading the internet" is a useful shorthand and a misleading one. What large language models actually do is process the output of a five-stage industrial filtering pipeline — one in which around 95% of published content is discarded before it ever shapes a model's knowledge. Understanding that pipeline, stage by stage, is the foundation of any serious AI content strategy.
AI systems are not trained on the web. They are trained on a highly compressed, filtered, and biased representation of it.
The Five-Stage Pipeline
Each stage is sequential and lossy. Content that fails at stage two never reaches stage three. The progression is: crawl → filter → tokenise → train → retrieve.
Stage 1: Raw Crawl — Casting the Net
Web crawlers collect raw content at scale: HTML pages, JavaScript, CSS, images, PDFs, and metadata including schema markup, HTTP headers, and robots.txt signals. At this point, nothing has been excluded yet — the crawl is indiscriminate.
The first transformation happens immediately after collection. Labs convert raw web content into a structured text representation. Every page becomes a record with roughly this shape:
- URL and title — canonical address and page heading
- Cleaned body text — HTML stripped to visible prose; boilerplate (navigation, footers, cookie banners, ads) removed
- Language detection — non-target-language content flagged
- Source quality signals — initial heuristic scores based on length, structure, entropy
Already at this stage, 60–90% of content is eliminated. Thin pages, templated output, duplicate URLs, spam, and SEO farms are removed before any human or quality classifier sees them.
Stage 2: Filtering & Curation — The Brutal Sort
This is where the decisive selection happens — and where most business content fails.
Labs apply multiple overlapping filters simultaneously:
- Quality classifiers — machine learning models trained to distinguish high-signal text from low-signal text, often using high-quality human-curated sources as positive examples
- Heuristics — minimum length thresholds, repetition ratios, entropy checks, punctuation density
- Source whitelists and blacklists — known-good domains are upweighted; known-spam domains are removed entirely
- Human-curated layers — books, academic papers, Wikipedia, and similar high-authority sources are added separately, often with multiple-epoch upsampling
The output is a set of curated sub-corpora: “web text”, “books”, “code”, “academic”, “instructional”. Generic marketing copy, thin blog posts, and duplicate content are not in any of these categories.
Stage 3: Tokenisation — The First True “Model Format”
Only after filtering and dataset assembly does tokenisation occur. This is where text becomes the actual input format that models process.
Algorithms used:
- BPE (Byte Pair Encoding) — used by GPT-series models; builds vocabulary from frequent character pairs
- SentencePiece — used by LLaMA and others; language-agnostic subword tokenisation
- Unigram language model tokenisers — probabilistic variant used in some multilingual models
The transformation: “AI visibility is driven by structure and trust” becomes [1543, 9821, 318, 7421, 416, 2937, 290, 4667]. The numbers are token IDs in a model-specific vocabulary. GPT and LLaMA use different vocabularies, so the same sentence produces different token sequences in each.
Two points that most content strategy discussions miss: tokenisation does not happen during crawling or early filtering; and the resulting vocabulary is model-specific, meaning there is no universal token representation of your content.
Stage 4: Model Training — Where Weights Form (Not Embeddings)
Here is the most persistent misconception in discussions about AI content strategy: content is not stored as embeddings inside a trained model.
What actually happens during training:
- Token sequences feed into the neural network as input
- Each token is converted to an embedding vector — a temporary, high-dimensional numerical representation
- These embeddings pass through transformer layers where attention patterns and representations are computed
- Weights across the network update via gradient descent — the model adjusts to predict the next token more accurately
- The embeddings used during this process are not retained — they are computational intermediates, not stored knowledge
The model's “knowledge” lives entirely in its weight matrices. When you interact with a language model, it does not retrieve stored text — it generates responses by running input tokens through layers of learned weights.
Content is ruthlessly filtered before it ever has a chance to influence AI systems. What survives does not sit in the model as text — it reshapes the model's statistical understanding of the world.
Stage 5: Embedding Usage — The Retrieval Layer
Embeddings do become explicit and persistent in one context: post-training retrieval systems. This is architecturally separate from base model training.
- RAG (Retrieval-Augmented Generation) — documents are embedded into vector representations and stored in a vector database; at inference time, the query is embedded and matched against stored document vectors
- Vector search — semantic similarity search across large document collections
- Evaluation and alignment datasets — embeddings used to measure model outputs against reference content
Understanding this distinction matters for content strategy: if you want your content to influence a model's base knowledge, you need to survive the training pipeline. If you want your content surfaced in a RAG system, you need to optimise for retrieval — a related but different set of structural requirements.
The Cumulative Discard Rate
The practical implication of the pipeline, expressed as retention estimates across stages:
- Raw crawl: 100% — everything collected
- After HTML cleaning and deduplication: ~30–40%
- After quality filtering: ~5–10%
- After final deduplication and curation: ~1–5%
- Effective influence on model behaviour: well below 1%
This is not a failure of the pipeline. It is the design. AI training datasets are precision instruments, not archives. The selection criteria are structural, not subjective — which means they can be understood, measured, and optimised for.
What This Means for Your Content
The five pipeline stages map directly onto the dimensions that determine whether content survives:
- Extractability → survives Stage 1 — clean HTML structure, semantic clarity, low boilerplate, readable without JavaScript
- Trust signals → survives Stage 2 — explicit authorship, schema markup, canonical URLs, citation patterns, factual density
- Cross-domain presence → survives selection bias — content that appears across multiple high-authority domains is harder to exclude
- Accessibility → gets crawled at all — robots.txt configuration, no JS-only rendering, fast load, no paywall on core pages
- Epistemic clarity → survives tokenisation and training intact — content that is structurally ambiguous produces weaker machine representations, poorer retrieval matches, and less reliable learned associations; the model may learn something, but not what you intended
Most content does not fail AI training pipelines because it is wrong or low-quality in any human sense. It fails because it lacks the structural signals that pipeline filters are calibrated to detect. That is a fixable problem — and the AI Knowledge Signal Framework is the systematic fix.
Last reviewed: May 2026 by Christopher Foster-McBride, Digital Human Assistants. Pipeline behaviour described here is derived from documented open pipelines (RefinedWeb, FineWeb). Proprietary model pipelines are undisclosed. Check the blog for updates.
Frequently Asked Questions
After crawling, content is converted into cleaned structured text — typically a record containing the URL, page title, stripped body text (HTML removed, boilerplate excluded), language tag, and initial quality signals. It is NOT in token or embedding format at this stage. Tokenisation only happens after quality filtering and dataset assembly are complete.
Tokenisation is the step immediately before training — not during crawling, not during filtering. Only content that has survived quality filtering and curation is tokenised. The tokeniser converts cleaned text into sequences of integer token IDs using algorithms like BPE (Byte Pair Encoding) or SentencePiece. Because vocabularies are model-specific, the same text produces different token sequences in GPT models versus LLaMA models.
No. This is a common misconception. During training, tokens are converted to embeddings — high-dimensional vector representations — as a computational intermediate. These embeddings are used in the forward pass and then discarded; they are not stored in the model. The model's knowledge is encoded in its weight matrices, not in stored text or fixed embeddings. Embeddings as persistent stored representations only appear in retrieval systems (RAG, vector databases) which are architecturally separate from the base model.
In documented open web-data pipelines, extraction, language filtering, quality filtering, and deduplication remove the majority of crawled documents. For strategy, the exact percentage matters less than the operational fact: most public web content does not become meaningful training or retrieval signal. The effective influence on model behaviour is even lower because higher-quality sources are heavily upsampled to dominate training. See RefinedWeb (2023) and FineWeb (2024) for documented pipeline removal rates. The discard rate is a feature, not a bug: AI training datasets are precision instruments. Understanding where in the pipeline your content is being excluded is the starting point for a content strategy that addresses AI representation.
Quality filters look for structural proxies of reliability and information density, not human-readable quality. Content that survives typically has: explicit authorship with verifiable credentials, schema markup that machine-parsers can extract, clear heading hierarchy (H1/H2/H3) that signals document structure, factual claims with cited sources, low boilerplate ratio (minimal nav, footer, and ad text relative to body content), original argument or data not duplicated across thousands of other pages, and clean HTML that renders meaningfully without JavaScript. The AI Knowledge Signal Audit evaluates any URL against these criteria and returns a Corpus Survival Likelihood rating.
A trained model's weights encode statistical patterns learned across the entire training corpus — they represent compressed, distributed knowledge that cannot be easily attributed back to individual source documents. A RAG embedding is a vector representation of a specific document, created at indexing time and stored in a vector database so that it can be retrieved by semantic similarity search. Weights are opaque and cannot be updated without retraining; RAG embeddings are explicit, inspectable, and can be added or removed from the retrieval index without touching the model. Optimising for base model training and optimising for RAG retrieval are related but distinct objectives.
Find out how AI systems represent you — then fix it.
The free AI Knowledge Signal Audit scores any public URL across five AI training readiness dimensions and returns a Corpus Survival Likelihood rating. The AI Knowledge Signal Framework — and the AI Knowledge Signal Chrome and Edge extension — give you the structure, audit, and re-score loop to fix what the audit finds.